纯文本社会科学指南:普通人的实用手册
- 原作者:Kieran Healy(杜克大学社会学教授)
- 链接:https://plain-text.co/
- 翻译说明:本翻译力求准确传达原文内容,保留技术术语和代码示例,原始版权归作者所有。
1. 引言
作为一名社会科学领域的初级研究生,你应该使用什么软件来完成工作?更重要的是,指导你做出选择的原则是什么?我提供一些总体考虑和具体建议。简而言之:你应该使用那些能让你对数据分析和写作过程有更多控制的工具。我建议你使用优秀的文本编辑器撰写文章和代码;使用 R 和 RStudio(或 Stata)进行定量数据分析;通过将工作存储在简单格式中(纯文本最佳)来最小化错误,并养成记录所做工作的习惯。对于数据分析,考虑使用 RMarkdown 等格式和 Knitr 等工具,让你未来的自己能够更轻松地重现工作。使用 Pandoc 将你的纯文本文档转换为 PDF、HTML 或 Word 文件以便与他人分享。将项目保存在版本控制系统中。定期备份所有内容。通过自动化尽可能多的步骤,让你的计算机为你工作。
为了帮助你入门,我提供了一套可直接使用的有用默认设置,帮助你开始使用 Emacs(一个强大、免费的文本编辑器)。我分享了一些模板和样式文件,可以让你快速从纯文本转换为各种输出格式。但我强调,这只是众多可行选择之一。我讨论了几种替代方案,因为任何有良知的人都不应该在未提供其他选项的情况下推荐 Emacs。
首先,我讨论为什么你应该关心更好地控制工作材料。我不想直接列出工具清单或复述它们的手册,而是希望鼓励你开始以一种能够找到适合自己解决方案的方式来思考这个问题。也许这意味着使用这里描述的工具,但也许不是。
动机
你可以使用各种软件设置来完成富有成效、可维护和可重现的工作。这是我不鼓励每个人转换到我使用的应用程序的主要原因。(我的原则是,如果我不能承诺在转换期间和之后提供技术支持,我就不会试图说服任何人切换。)因此,本讨论不是旨在说服你存在唯一的正确组织方式。然而,我确实认为,如果你正处于研究生生涯的早期阶段(例如社会学、经济学或政治学),你应该认真思考如何组织和管理你的工作。这有两个原因。首先,向研究生的过渡是做出改变的好时机。早期阶段,转换的惯性和成本都比以后要少。其次,在社会科学中,文本和数据管理技能通常不会明确地教授给学生。这意味着你可能最终会采用导师的做法,继续使用方法课程中所学的内容,或者简单地复制同龄人的做法。遵循这些路径可能会让你找到满意的安排,但也可能不会。值得考虑各种选择。
开篇有两点说明。首先,因为本讨论针对初学者,一些读者可能已经熟悉其中很多内容。其次,尽管在下文中我主张你特别关注一下某些应用程序,但这并不是关于工具或实用程序本身。组织的禅意不在于花哨的软件。完成任务的真正路径也不会通过购买一个漂亮的 Moleskine 笔记本而向你揭示。不幸的是,它存在于内心。
计算机的两场革命
在就这个主题与本科生或研究生交流时,以及在教授使用这些工具的课程时,我越来越遇到一个问题:如果不先退后一步讨论他们正在使用的计算机是如何工作的,就很难入门。我认为原因是以平板、触屏为基础的计算机模式的兴起,最明显的是在手机上,其次是在 iPad 或 Surface 平板等设备上。现在,大多数需要撰写长文档(如论文或学位论文)或深入处理数据的人并不会将平板作为主要设备。但似乎很清楚,某种触摸屏交互是大多数人计算的未来。事实上,一旦适当考虑手机,你就会意识到这是大多数人计算的现在。
虽然并非完全不可能,但在这种设备上进行学术性的社会科学工作仍然非常困难。这种情况很可能还会持续一段时间。我们现有的工具不是为它们设计的。我认为这里存在一个被低估的紧张关系。两场正在进行的计算革命倾向于朝相反方向拉扯。
- 一方面,移动、云中心、触屏、手机或平板模式将强大的计算能力带给了比以往更多的人。这是每个人都在谈论的革命,因为它发生在大规模上,而且是所有资金的流向。它将单一用途的应用程序置于前景。它向用户隐藏了操作系统的工作原理,并竭力简化或完全隐藏文件系统的结构,而文件系统是存储和移动项目的地方。
- 另一方面,用于纯文本编码、数据分析和写作的开源工具也比以往任何时候都更好、更易获得。这当然发生在比第一场革命更小的规模上。但这些工具确实彻底改变了数据分析和科学计算的可用性和实践。它们仍在继续这样做,因为人们努力使其在从网络抓取数据到展示结果的各个方面都做得更好。这些工具主要通过将独立的、专门的小部件连接起来形成可重现的工作流程来工作。它们是 " 零碎 " 或颗粒化的,因为数据分析过程本身也是如此。这些工具在隐藏操作系统层方面做得少得多——相反,它们经常直接与操作系统交互——而且它们通常预先假定研究者对文件系统有工作知识,文件系统组织着他们使用的所有东西,从数据文件到代码、图表和最终论文。
这种紧张关系在于,越来越多进入社会科学世界并对数据工作感到兴奋的人,也往往很少或没有使用基于文本、命令行、依赖文件系统的工具的先验经验。在许多情况下,他们也没有充分利用多任务窗口环境的经验,即知道如何让应用程序协同工作以实现单一目标。需要明确的是,这不是用户的错。这也不是我对命令行的某种错位的怀旧。相反,这是计算机使用在非常大规模上发生变化的一个方面。我们拥有的编码和数据分析工具是强大的,并且在大多数情况下旨在允许研究产品被打开和检查。但它们的工作方式与日常、终端用户计算的趋势相悖,后者隐藏实现细节并专注于单一用途的任务。短期内对社会科学的净结果是我们将拥有一套强大且非常有用的工具,在开放环境中开发,由乐于助人的社区支持,并且大多可免费获得。但当你刚开始时,教人们如何使用它们将变得更加困难,甚至可能一开始就无法说服人们尝试它们。
问题是什么?
问题在于学术工作本质上是混乱的。当然,有将想法写下来这种烦人的事,但也有之前、期间和周围的一切:数据分析及其伴随的一切,以及学术论文不可避免的繁琐机制——特别是引用和参考文献。有很多东西需要跟踪,有很多东西需要正确处理,有很多东西需要在写作时整合在一起。学术论文绝不是唯一受此类约束的写作形式。考虑一下咨询工程师 Dr. Drang(化名)的这段合理讨论:
我通常做的那种写作……充满了事实。我经常参考照片、图纸、实验测试结果、计算、他人撰写的报告、教科书、期刊文章等等。这些不是干扰;它们是写作过程的重要组成部分。 而且不仅仅是参考资料。很多时候我需要制作自己的图表和图纸以包含在报告中。因为文本和图表都是一个连贯整体的一部分,我需要在两者之间来回切换;文字为图片提供信息,图片也为文字提供信息。这不是在无干扰(distraction-free)的编辑器视频中看到的那种柏拉图式的理想清洁写作环境——空桌子上的白房间里放着一杯咖啡。 这些编辑器的部分流行是对多任务处理的反弹,但人们混淆了自己和计算机。当我写报告时,这是我的单一任务,我会使用任何必要的工具来完成它。我的计算机通过同时运行多个程序来实现多任务,这不是混乱或干扰的来源,而是让我完成单一任务的自然而高效的方式。
很多学术写作就是这样。管理起来可能很棘手。当你有合作者和其他贡献者时,情况更糟。那么,该怎么办?
办公模式(Office Model)与工程模式(Engineering Model)
让我做一个粗略的区分。这个问题有“办公型”解决方案,也有“工程型”解决方案。不要纠结于这种区分或标签。办公型解决方案倾向于以 Microsoft Word 这类工具为中心的工作集群。Word 文件或文件集是你工作中最“真实”的东西。对工作所做的更改在该文件或多个文件内部跟踪。引用和参考管理器插入这些文件中。数据分析的输出(表格、图表)也被剪切粘贴进去,或保存在它们旁边。主文档可能在人与人之间传递以进行编辑和更新。最终输出从它导出,也许是 PDF 或 HTML,但也许最常见的最终输出只是清理过并关闭修订功能的 .docx 文件。
与此同时,在工程模式中,纯文本文件处于你工作的中心。项目中最“真实”的东西要么是这些文件,更可能是存储项目的版本控制仓库。更改在文件之外跟踪,同样使用版本控制系统。数据分析在代码中管理,以(理想情况下)已知且可重现的方式产生输出。引用和参考管理也可能以纯文本完成,如 BibTeX 的 .bib 文件。最终输出从纯文本组装,并使用某种排版或转换工具转换为 .tex、.html 或 .pdf。很多时候,由于世界上某些不可避免的事实,这种解决方案的最终输出也是一个 .docx 文件。
这种区分旨在捕捉组织上的倾向,而非刚性划分——更不是某种性格类型。显然,可以按办公模式组织事物。(事实上,这是主导方式。)像 Scrivener 这样的应用程序同时结合了两种方法的元素。Scrivener 有效地拥抱了大型写作项目的“零碎性”,并能以各种格式输出干净副本。Scrivener 是为撰写长篇小说(或定性非虚构)的人而非定量数据分析而构建的,因此我从未广泛使用过它。与此同时,Microsoft Word 仍然统治着人文学科和社会科学的大片领域,以及许多出版商的制作流程。因此,即使出于其他原因你更喜欢纯文本——特别是在项目管理和数据分析方面——需要或必须向某人提供 Word 文档是想要能够轻松转换事物的主要原因之一。HTML 是很好的通用语言。
我主要关注工程模式。但许多人使用办公模式,你可能最终会与(或为)其中一些人一起工作。在这些情况下,通常你使用他们的软件比反过来更容易,如果仅仅因为你的电脑上很可能已经安装了 Word。在这些情况下,你也可能使用 Google Docs 或其他允许同时编辑主文档副本的服务进行协作。这可能不理想,但总比不协作好。在 .docx 世界中,纯文本的教条主义几乎没有好处。
2. 做好记录
确保知道自己在做什么
对于任何导致学术论文的正式数据分析,无论你倾向哪种模式,都应遵循一些基本原则。也许最重要的事情是以一种能留下行动连贯记录的方式工作。例如,不要只是做一些统计工作,然后只保留你产生的结果表格或图形,而应该将你做的事情记录为有文档的代码。与其解决了一个可能再次遇到的问题却没有记录,不如将答案写成明确的程序。与其在没有太多上下文的情况下复制一些档案材料,不如妥善归档来源,或至少精确引用它。
第二个原则是文档、文件或文件夹应该总能告诉你它是什么。除了让你的工作可重现之外,你还需要一些方法来组织和记录你的论文草稿、代码、田野笔记、数据集、输出文件或任何你正在处理的东西。在文件易于搜索的世界中,这可能只意味着将你的作品保存在纯文本中并赋予描述性名称。它通常不应该意味着投入时间创建某种精心设计的分类方案或目录,这本身会成为维护的负担。
第三个原则是重复且容易出错的过程应该尽可能自动化。(软件开发人员称之为“DRY”或“不要重复自己”。)这使得检查和纠正错误更容易。与其一遍又一遍地复制粘贴代码来对数据的不同部分做基本相同的事情,不如编写一个通用函数,在需要时调用。与其在每次向期刊投稿时都重新输入和重新格式化参考文献,不如使用能自动为你管理这些的软件。
有很多方法可以实现这些原则。你可以使用 Microsoft Word、Endnote 和 SPSS。或 Textpad 和 Stata。或一堆法律便笺、计算器、剪刀和文件盒。但软件应用程序并非生而平等,有些比其他更容易做正确的事。例如,可以使用 Microsoft Word 制作结构良好、易于维护的文档。但你必须严格且负责任地使用其样式和大纲功能,而大多数人不会费心。你可以在 SPSS 中维护可重现的分析,但应用程序并未设置自动或高效地执行此操作,其设计也不鼓励良好习惯。因此,花点时间了解替代品可能是个好主意。其中许多可以免费使用或试用,而你正处于职业生涯中可以承受尝试不同设置而不太麻烦的节点。
你撰写的学位论文、书籍或文章通常包括正文、数据分析结果(可能以表格或图形呈现)以及注释和参考文献的学术工具。因此,在整理论文或整个学位论文时,你希望能够轻松地以可重现的方式记录你在编辑文本、分析数据和展示结果时的行动。在下一节中,我将描述一些为此设计的应用程序和工具。我专注于那些很好地协同工作(通过设计)且都可免费用于 Windows、Linux 和 Mac OS X 的工具。它们绝非完美——事实上,其中一些学习起来可能很别扭。但研究生级别的研究和写作也可能很难学。专门的任需要专门的工具,不幸的是,尽管它们非常擅长自己的任务,但这些工具并不总是刻意友好。
使用版本控制
写作涉及大量编辑和修订。数据分析涉及清理文件、可视化信息、运行模型,以及反复重新检查代码中的错误。你需要跟踪这项工作。随着项目的增长和变化,以及你探索不同的想法或探究方向,记录文件中特定代码片段或段落编辑的工作可能随时间推移而变得更加复杂。最好的做法是建立某种版本控制,以保留对单个文件、材料文件夹或整个项目的更改的完整记录。良好的版本控制系统允许你“倒带”(rewind the tape)到笔记、草稿、论文和代码的早期版本。它让你能够探索项目的不同方面或分支。在其更发达的形式中,它为你提供了与他人协作的强大工具。它帮助你避免目录充满名字令人困惑的相似文件,如 Paper-1.doc、Paper-2.doc、Paper-conferenceversion.doc、Paper-Final-revised-DONE-lastedits.doc。
在社会科学和人文学科中,你最可能通过 Microsoft Word 的“跟踪更改”功能接触到系统版本控制的概念,该功能让你看到自己和合作者对文档所做的编辑。通过 Google Docs 或 Quip 等平台对单个文档进行协作编辑也是可能的。真正的版本控制是一种以全面透明的方式对整个项目而不仅仅是单个文档执行这些操作的方法。现代版本控制系统如 Mercurial 和 Git 可以在需要时管理具有许多分支、分布在多个用户中的非常大的项目。Git 已成为事实上的标准,GitHub 是软件开发人员和社会科学家公开工作的地方,也是你可以贡献正在进行的项目或公开自己作品的地方。
现代版本控制需要适应一些与跟踪文件相关的新概念,并学习版本控制系统如何实现这些概念。有一些很好的资源可以学习它们。由于其强大功能,这些工具对个人用户来说可能看起来过于复杂。(但同样,许多人一旦开始使用 Word 的“跟踪更改”功能就发现它不可或缺。)但版本控制系统可以以相当直接的方式在基本层面上使用,而且通常可以轻松集成到你的文本编辑器中,或通过更友好的应用程序界面使用,让你远离命令行。核心思想如图 2.1 所示。你将工作保存在仓库中。这可以保存在本地或远程服务器上。工作时,你定期暂存更改,然后将它们提交到仓库,并附上关于所做工作的简短说明。仓库可以被你或他人复制、克隆、合并和贡献。
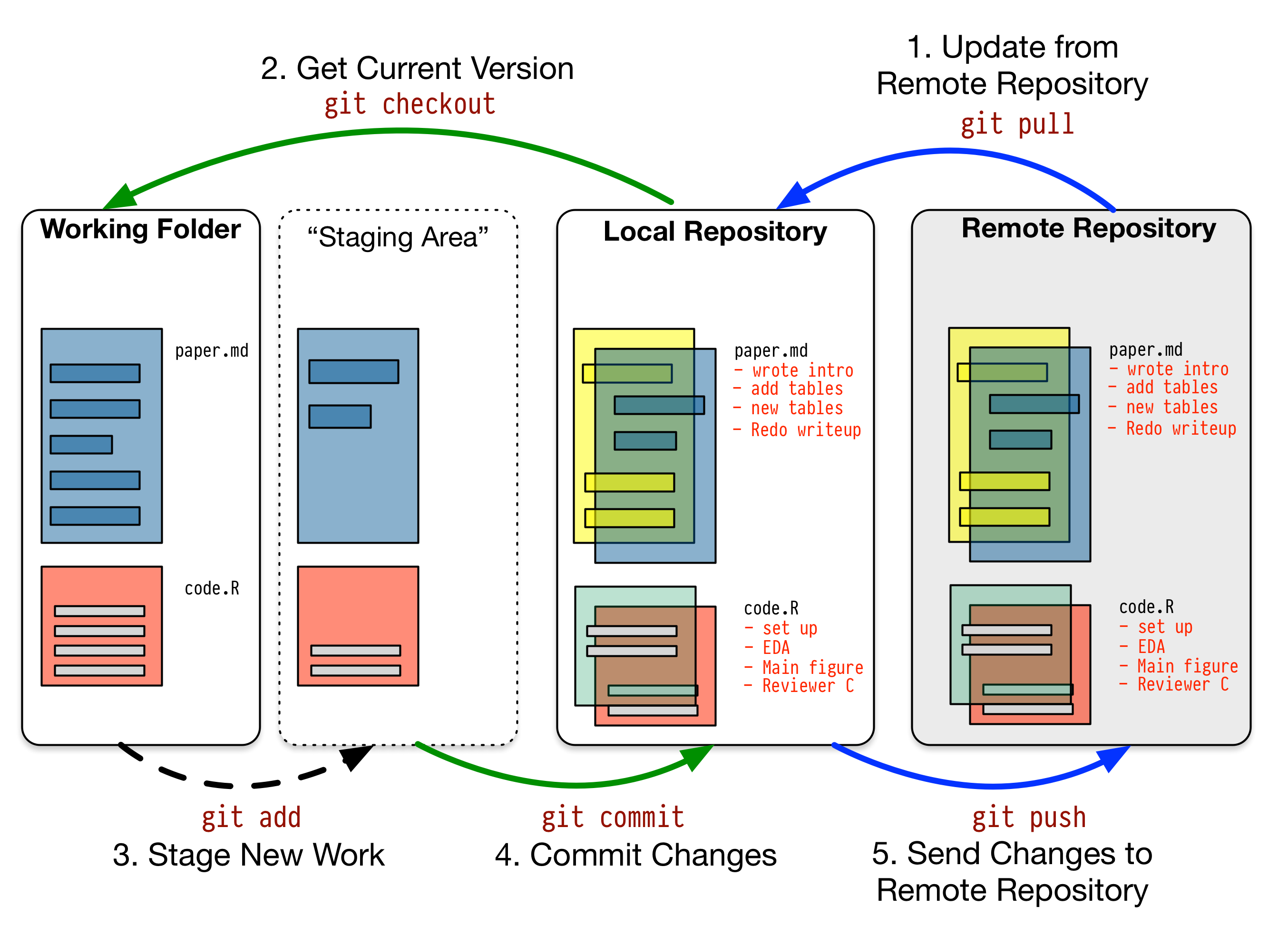
Figure 2.1: A schematic git workflow.
图 2.1 描述了一个简化的 git 工作流程。你从远程仓库(如 GitHub)获取项目的最新版本,然后“检出”项目进行工作,编写代码或文本。你像往常一样在计算机上的文件夹中处理文件。但仓库才是项目而言“真实”的东西。一旦你对文档所做的更改感到满意,你就暂存这些更改。在幕后,这意味着更改被添加到 Git 用于跟踪事物的索引中。但这些更改尚未被永久记录。为了使它们永久化,你将更改提交到仓库,并附上关于所做工作的说明。你现在有了行动的可靠记录。然后你将更改“推送”到远程仓库,这在实际上也起到了备份工作的作用。随时间推移,仓库包含了项目的完整记录,任何步骤都可以按需重新访问。在最简单的情况下,没有远程仓库,只有你检出和提交更改的本地仓库。你可以从命令行完成所有这些操作,或使用几个设计用于帮助你管理事务的前端应用程序之一。
修订控制有显著好处。像 Git 这样的工具结合了“跟踪更改”和备份的优点。每个仓库都是项目的完整、自包含、加密签名的副本,带有其发展每一步由所有参与者记录的日志。它让你养成在文件或项目开发过程中逐步提交更改并(简要)记录这些更改的习惯。它允许你通过创建项目的“分支”轻松测试不同发展思路或思考方向。它允许协作者同时处理项目,而无需通过电子邮件来回发送无尽的“主”副本版本。它提供了强大的工具,允许你自动合并或(必要时)手动比较你或他人所做的更改。也许最重要的是,它让你能够随意重新访问项目开发的任何阶段,并重建你当时正在做的事情。这在编写定量分析代码、管理田野笔记或撰写论文时都很有用。虽然你可能不需要以这种方式控制一切,但我强烈建议你至少考虑管理构成项目核心的文本文件组(例如进行分析并生成表格和图表的代码;数据集本身;你的笔记和工作论文;学位论文的章节等)。随时间推移,你将生成一个广泛、带注释的行动记录,这也是项目每个发展阶段的备份。像 GitHub 这样的服务允许你存储公开或(付费)私人项目仓库,因此也可以成为异地备份工作以及协作和记录文档的平台。
你下载并安装 Git 后(例如通过安装 Apple 的开发者工具),开始使用它的最简单方法是创建 GitHub 账户,然后配置 git 和 GitHub。虽然 git 是免费软件;GitHub 是带有免费层级的商业服务。
你为什么要费心做这些?因为你这样做主要是为了你自己。论文需要很长时间才能写完。当你不可避免地需要在九个月后返回你的表格、图表或引文时,你未来的自己将省去数小时花在想知道你在想什么以及从哪里得到它的时间。
备份工作
无论你选择使用正式的修订控制系统,你还是应该有一些系统化的方法来跟踪文件的版本。如果将仓库保存在工作计算机以外的地方,版本控制项目在一定程度上已备份。但这远远不够。例如,Apple 的 Time Machine 软件将文件备份和版本化到磁盘或本地硬盘,允许你回到你想要的文件的特定实例。但这仍然不够。你需要定期、冗余、自动、异地的工作备份。因为你是懒惰且倾向于 magical thinking 的,你不会负责任地自己做这件事。这就是为什么最有用的备份系统是那些需要最少工作量来设置,一旦组织好,就自动备份一切而不需要你必须记住做任何事情的系统。这意味着支付像 Crashplan 或 Backblaze 这样的安全异地备份服务。异地备份意味着在(不太可能但并非闻所未闻的)事件发生时,你的计算机和本地备份被盗或被毁,你仍然拥有文件的副本。我认识一个人,她的办公楼被龙卷风击中。她回来时发现文件和计算机泡在一英尺深的水里。你永远不知道。不那么戏剧性,但从工作角度来看同样灾难性的是,我认识一些人因为掉落笔记本电脑、被盗,或仅仅因为计算机(或 " 备份驱动器 ")无缘无故地故障而丢失数月甚至数年的工作。就像安全带一样,你不需要备份,直到你真正、真正需要它们。正如 Jamie Zawinski 所说,当谈到丢失数据时,“宇宙倾向于最大讽刺。不要挑战它。”(The universe tends toward maximum irony. Don't push it.)
3. 写作与编辑
使用文本编辑器
如果你要进行任何形式的定量分析,那么你应该使用良好的文本编辑器写作。我认为这也适用于处理任何高结构、经历大量修订的文档,如学术论文。文本编辑器与文字处理器不同。与 Microsoft Word 等应用程序不同,文本编辑器通常不会努力让你写的东西看起来像印在纸上。相反,它们专注于高效处理文本,同时将其保持在简单且可移植的格式中,而不是像 .docx 这样的二进制文件格式。图 3.1 显示了一个示例。
Figure 3.1: Working on part of this document in Emacs.
文本编辑器也能在文字处理器不太有用的地方帮助你。例如,如果你编写代码进行统计分析,一个好的编辑器至少会以某种方式突出显示关键词和运算符,使代码更具可读性。通常,它也会在你犯语法错误时(例如忘记右大括号、分号或引号)被动地发出信号,并在你编写代码时自动缩进或整理代码。更高级的编辑器可以与 linter 配合使用,在你编写时更主动地检查和标记风格或语法错误。如果你正在撰写包含任何类型数据的学术论文或学位论文,特别是数值数据,一个好的文本编辑器可以让你更容易地控制事物。正如实际数字由你的统计程序而非文本编辑器处理一样,论文的排版也由专用应用程序处理。该工具应自动处理参考文献条目、表格和图表标签、交叉引用等事项。最好的编辑器可以与你用于完成工作各个部分的工具紧密集成。
Emacs 是一个文本编辑器,就像蓝鲸是哺乳动物一样。它做我刚才描述的这些事情,如果你愿意,还可以做更多。将 Emacs 与其他一些应用程序和插件结合起来,可以有效地管理写作和数据分析。如果在编辑器中执行一堆不同任务似乎很奇怪,博主 Rekado 对人们使用网络浏览器的方式做了一个有用的类比:
就像浏览器被许多人用作运行基于 HTML 文档的应用程序的平台一样,Emacs 是将任何可以“合理地”(这有待解释)映射到文本缓冲区的事物的平台。浏览器中的应用程序用 JavaScript 编写,Emacs 中的应用程序用 Emacs Lisp(也称为 elisp)编写……如果你曾使用网络浏览器(或观察过某人使用网络浏览器)玩游戏、听音乐、看视频、阅读和撰写电子邮件、编辑文本(例如为维基百科做贡献)、与朋友聊天(或谈论敌人)、阅读文档、安装扩展——那么通用工具作为平台的概念对你来说应该不陌生。Emacs 可以被理解为提供文本接口(其中之一可能是文件编辑器)的这类通用工具。
虽然非常强大和灵活,但 Emacs 可能令人讨厌。事实上,对许多首次接触它的人来说——特别是那些习惯 Windows 或 Mac OS 标准应用程序的人——它的惯例似乎古怪且拜占庭式。作为应用程序,Emacs 相当古老。第一个版本由 Richard Stallman 在 1970 年代编写。因为它在更早期的计算时代演化(例如在像样的图形显示器、窗口管理器出现之前,可能还在火之前),它不具有许多现代应用程序的惯例。像大多数强大的文本编辑器一样,Emacs 提供了许多浪费你时间学习其特定惯例、调整其设置和一般性地定制它的机会。每个主要平台都有几个很好的替代品。
既然如此,为什么要首先提到它?部分因为这是我使用的编辑器。部分因为它可用于所有主要的桌面和笔记本电脑计算平台。部分因为它非常、非常擅长做我想让它做的事情。使用像 TextMate 或 Sublime Text 这样的东西而不是 Emacs 有很多很好的理由。同样,在使用 R 进行数据分析时,你可能只想使用 RStudio 环境。如果你选择这些替代品,你会做得很好。
使用 Markdown
当你用纯文本撰写论文时,如何管理格式化、分节和文档的其他相关方面?Markdown 是一种松散标准化的编写纯文本的方式,包含有关文档格式化的信息。它最初由 John Gruber 开发,Aaron Swartz 提供了输入。目标是创建一种简单的格式,能够整合文档的结构信息(如标题和子标题、强调、超链接、列表、脚注等),同时最大程度地减少可读性的损失。像 HTML 或 TeX 这样的格式是更加广泛的标记语言,但 Markdown 旨在简单。多年来它已成为事实上的标准。文本编辑器和笔记应用程序支持它,存在将 Markdown 转换不仅是 HTML(其原始目标输出格式)而且许多其他文档类型的工具。清单 1 显示了本文档部分的 markdown 源代码。
清单 1:本文档附近部分的 markdown 源代码
When you write papers in plain text, how do you manage the formatting,
sectioning, and other related aspects of your document?
[Markdown](http://en.wikipedia.org/wiki/Markdown) is a
loosely-standardized way. It was originally developed by John Gruber,
with input from Aaron Swartz. The aim was to make a simple format
that could incorporate structural information about the document
(such as headings and subheadings, *emphasis*,
[hyperlinks](http://daringfireball.net/markdown), lists, footnotes,
and so on), with minimal loss of readability. Formats like HTML or TeX
are much more extensive markup languages, but Markdown was meant to be
simple. Over the years it has become a *de facto* standard. Text
editors and note-taking applications support it, and tools exist to
convert Markdown not just into HTML (its original target output
format) but many other document types as well. @lst:markdown-example shows
the markdown source for this paragraph and its subheading.
清单 1 中显示的摘录展示了一些最常见的 Markdown 约定,最值得注意的是它如何表示标题和子标题(顶级标题使用 # 符号,下一级使用 ##,依此类推)、如何表示超链接以及如何强调文本。一旦你的文本以这种格式标记,你需要一点软件才能从那里获得正确可读的 HTML、PDF 或 Word 文件。这就是 pandoc 的用途——稍后详述。
有许多 Markdown 变体或“风味”(flavors),已扩展它以管理交叉引用、标签、引用和其他文本元素。我推荐使用 Pandoc 的 markdown,它可以处理所有这些。这意味着你可以使用 Markdown 编写纯文本,而不用担心参考文献列表是否完整,或在你移动文本内容后交叉引用(例如对图 3)是否仍然正确。
结合 ESS 或 RStudio 使用 R
你可能会进行大量定量数据分析。R 是一个统计计算环境。它得到良好支持,持续改进,并拥有非常活跃的专家用户社区。软件附带文档完整,虽然有点简洁,但也有大量优秀的参考和教学文本说明其使用方法。这些包括 Dalgaard(2008)、Venables & Ripley(2002)、Maindonald & Braun(2003)、Fox(2002)、Harrell(2016)、Matloff(2011)和 Gelman & Hill(2007)。虽然它在核心上是一个命令行工具,但可以轻松与 RStudio IDE 结合使用。你可以从 R 项目主页下载 R。
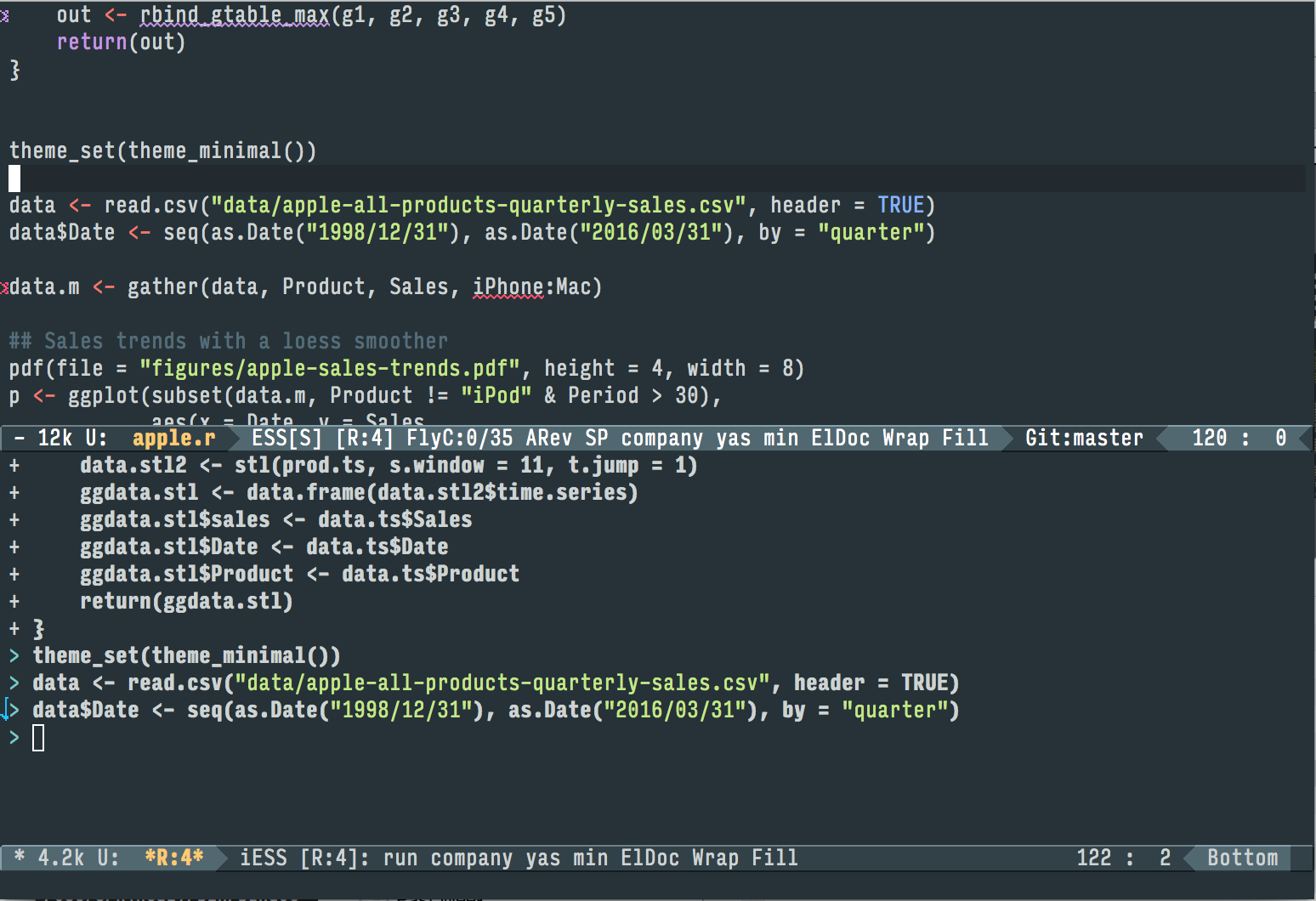
Figure 3.2: Working with R in Emacs using ESS. A document containing R code is open in the top half of the screen. Below the divider, an R session is running, also inside Emacs. Code from the top pane is sent to the bottom with a keyboard shortcut, where it is evaluated by R. We can also jump down to the bottom pane and do work there. Small details like a lint checker, active line highlighting, and revision-control information are also visible.
R 可以通过名为 ESS(Emacs Speaks Statistics)的包直接在 Emacs 内使用。如图 3.2 所示,它允许你在 Emacs 框架中处理代码,并在旁边的另一个框架中运行实时 R 会话。因为一切都在 Emacs 内部,所以很容易使用快捷键将代码块发送到 R。这是在构建未来可重复使用的代码时进行交互式数据分析的非常高效的方式。
你将在论文中展示结果,也会在演讲中使用某种演示软件展示。你可以使用 Microsoft PowerPoint 或 Apple 的 Keynote。或者,你可以直接从纯文本文档生成 HTML 或 PDF 幻灯片。
4. 重现工作
最小化错误
我们已经看到,正确的工具集可以通过自动突出显示代码语法、确保你引用的所有内容都进入参考文献、找出语法错误以及为常用方法或函数提供模板来节省时间。你的时间在两个方面得到节省:你不会重复自己,也会减少原本需要修复的错误。在管理正在进行的项目时,最小化错误意味着解决两个相关问题。第一个是找到进一步减少错误在不被注意的情况下潜入的机会的方法。这在编码和分析数据时尤其重要。第二个是找到一种方法,回顾性地弄清楚你做了什么来产生特定结果。使用修订控制系统让我们在实现这一目标方面走了很长一段路。但在特定报告或论文层面,我们还可以做更多。
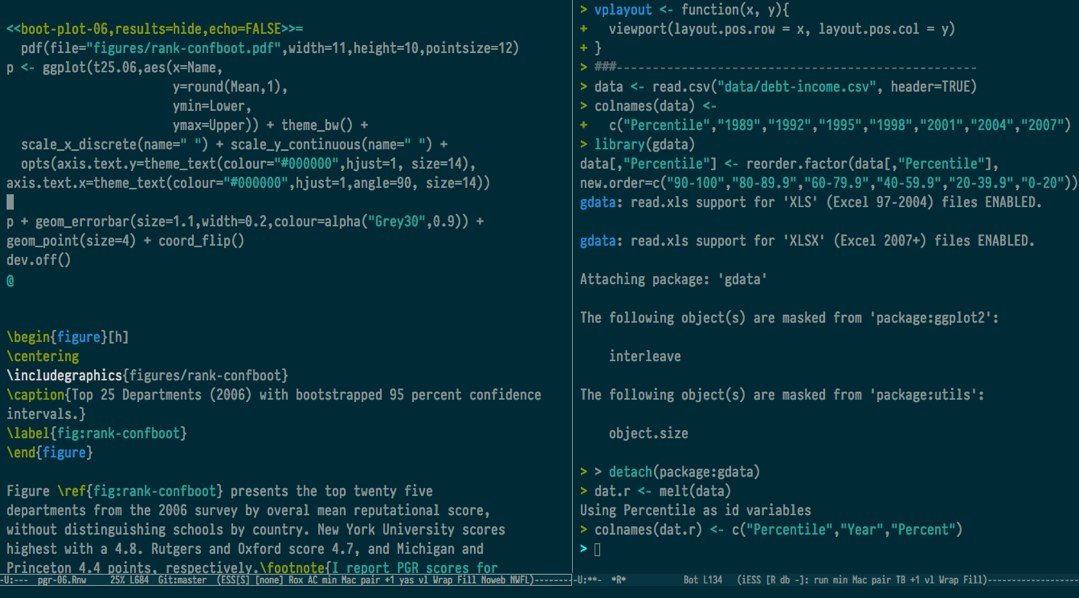
编写代码通常是在进行某种分析的过程中进行的。你产生想法,有几个想看的东西,一件事导致另一件事。一般来说,你应该尝试在过程中记录工作。如果你编写 R 脚本,这通常意味着向工作中添加(简短但有用)的注释,以解释一段代码的意图。这也意味着应该努力编写可读的代码。在这方面,代码就像散文。Hadley Wickham 的 R 风格指南提供了编写可读代码的一些有用指导。R 包 lintr 实现了这些原则——它像代码的文案编辑。在 Emacs 中,你可以通过名为 flycheck 的工具自动使用 lintr。
编写代码时还应尝试不重复自己。一条好规则是,如果你发现自己在复制粘贴代码块(例如,为许多不同变量绘制相同类型的图表或运行相同类型的模型),你应该暂停一下,看看是否可以编写一个快速便利函数来更有效地自动化事物。这样,你的代码可以更短,也更不容易出现通过重复复制粘贴潜入的错误和不一致。
从服务器场到数据表
数据分析中的错误往往从论文中用于生成图形或表格的过程与后续使用该输出之间的典型差距中产生。在通常的做法中,你在一个文件中保存数据分析代码,另一个文件中保存其产生的输出,第三个文件中保存论文文本。你进行分析,收集输出,并将相关结果复制到论文中,通常在路上手动重新格式化。这些转换每一步都引入了出错的机会。特别是,结果表格很容易与产生它的一系列步骤分离。几乎所有撰写过定量论文的人都曾遇到过阅读包含需要重新审视或重现(例如由于同行评审)的结果或图表的旧草稿,但缺乏关于其创建情况的任何信息的问题。学术论文需要很长时间才能完成写作、评审、修订和发表的周期,即使你一直努力工作。经常需要返回两年前做的东西来回答评审者的某个问题。你不想为了得到正确答案而不得不从头再做一遍所有事情。毫不夸张地说,无论重现他人定量分析的结果有什么挑战,在相当短的时间内,作者自己就很难重现自己的工作。计算机科学人士有一个术语,描述仅仅因为项目被留在硬盘上六个月或更长时间而不可避免发生的衰败过程:bit-rot。
使用 RMarkdown 和 knitr
填补这一差距的一个重要方法是在 R 中进行定量分析时使用 RMarkdown 和 knitr。我们已经看到了如何在 Markdown 的轻量级格式中编写纯文本文档。RMarkdown 允许你将代码整合到这一过程中。它旨在整合数据分析的纯文本文档或写作及其执行。你像往常一样撰写论文文本(或更常见的是记录数据分析的报告)。每当你想运行模型、生成表格或显示图形时,你不是从其他地方粘贴结果,而是写下将产生你想要输出的 R 代码。这些“代码块” 可以散布在整个文档中。它们由块开头和结尾的特殊分隔符与普通文本区分开来。
当你准备好时,你就编织(knit)文档(Xie,2015)。也就是说,你将 .Rmd 文件喂给 R,R 处理代码块,并生成一个新的 .md 文件,其中代码块已被其输出替换。然后你可以将该 Markdown 文件转换为 PDF 或 HTML 文档。相关地,R 中的 rmarkdown 库提供了 render() 函数,可让你从 .Rmd 一步到 HTML 或 PDF。这是 RStudio 用于生成文档的功能。反之,如果你只想从周围文本中提取你编写的代码,则“拆解”(tangle)文件,结果为 .R 文件。在实践中这很直接。这种方法的优点是它使正确记录工作变得容易得多。数据分析和写作只有一个文件。分析的输出是即时创建的,执行操作的代码嵌入在论文中。如果你需要对不同数据片段进行多次但相同(或非常相似)的分析,RMarkdown 和 knitr 可以让生成一致可靠的报告变得更加容易。
RMarkdown 是几种文学编程(literate programming) 格式之一。这个想法可以追溯到 Donald Knuth,这位开拓性的计算机科学理论家在他的业余时间开发了 TeX 排版系统。虽然他的重点是文档化计算机程序,但回想起来,Knuth 预见了可重现数据分析的许多主要思想——并开发了几个初始工具。例如,图 4.1 可以从包含在本文 .Rmd 源代码中的源代码块即时生成。有时我们只想显示代码产生的结果——在这种情况下是图 4.1。但在其他时候,我们也想显示代码,如下所示:
library(ggplot2)
tea <- rnorm(100)
biscuits <- tea + rnorm(100, 0, 1.3)
data <- data.frame(tea, biscuits)
p <- ggplot(data, aes(x = tea, y = biscuits)) +
geom_point() +
geom_smooth(method = "lm") +
labs(x = "Tea", y = "Biscuits") + theme_bw()
print(p)
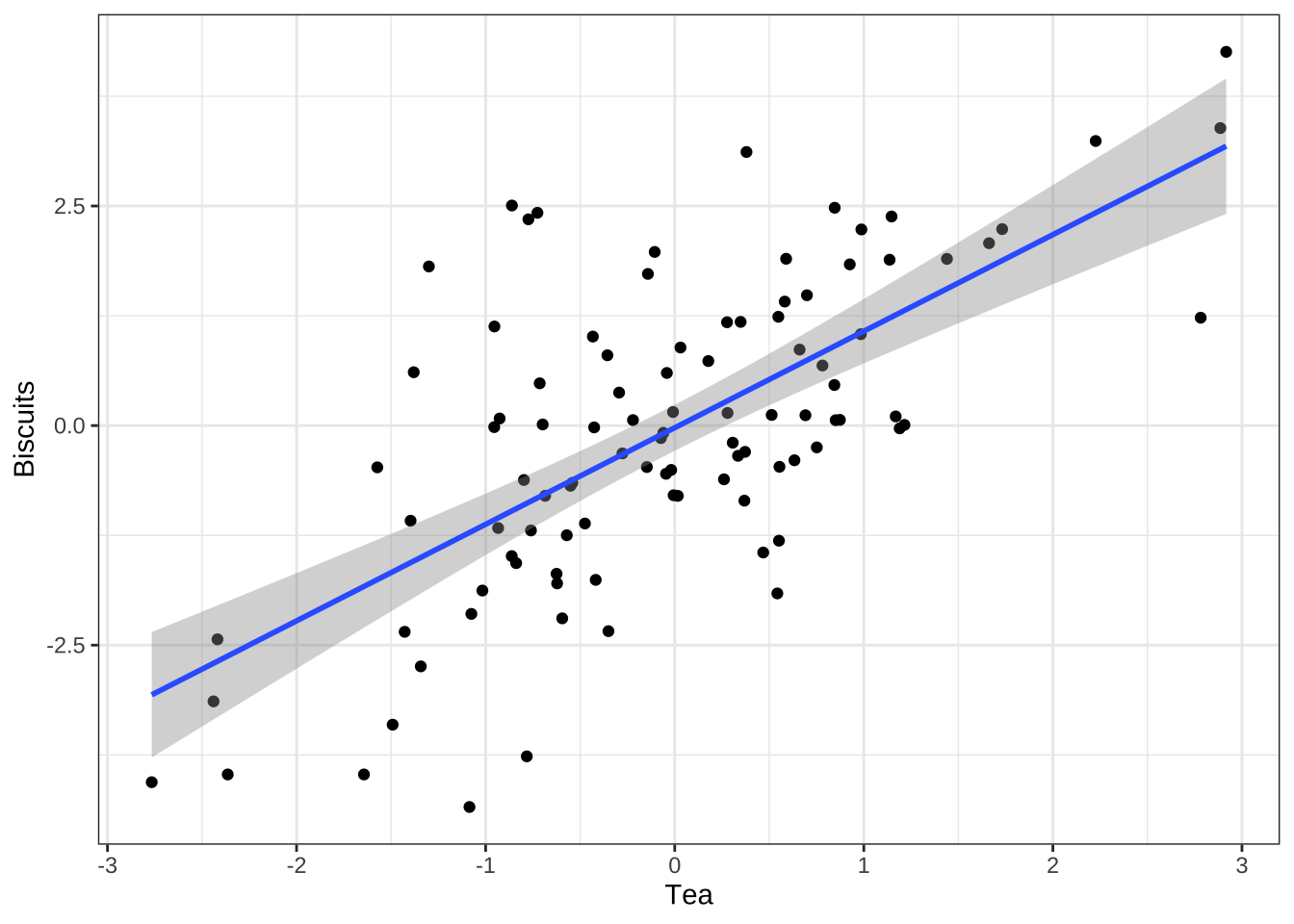
Figure 4.1: R code for a figure.
knitr 库和 RMarkdown 也让生成 HTML 输出变得容易。这使得便携性、转换和编辑时的快速预览变得容易。你可以在 RStudio 之外的任何文本编辑器中使用 RMarkdown 文件,Emacs 对它们有强大支持。RStudio 也内置了对 .Rmd 文件的支持,使生成 HTML 和 PDF 输出非常容易,并通过其 RPubs 服务将你的报告发布到网络上。
knitr 网站有许多展示其工作原理的示例,范围从基本设置到更复杂的例子。
文学编程方法有其局限。对于大型或复杂的分析,分块产生最终结果仍然比在单个 .Rmd 文件中一次性完成更有意义。这是使用某种版本控制管理项目仍然重要的原因之一,因此你可以跟踪可能不适合单个 .Rmd 文档内但必要的工作。
RStudio 的 Rmarkdown 支持使用此处描述的所有相同工具——即 knitr、pandoc 等。通过 RStudio 编写 RMarkdown 文档是使用纯文本源和 R 生成完成的论文和报告的最简单方式。
5. 整合所有内容
我们撰写论文。这些论文引用书籍和文章。它们经常整合在 R 中创建的表格和图表。我们想要做的是快速将包含这些内容的 Markdown 文件转换为正确格式化的学术论文,而不放弃任何必要的学术工具(在输出侧)或 Markdown 的便利性和可转换性(在输入侧)。我们想轻松地从同一来源在 HTML、PDF 和 DOCX 格式中获得好看的输出。我们希望以绝对最少——理想情况下为零——的输出后处理来实现这一点,只需基本转换步骤。这是我们力所能及的。
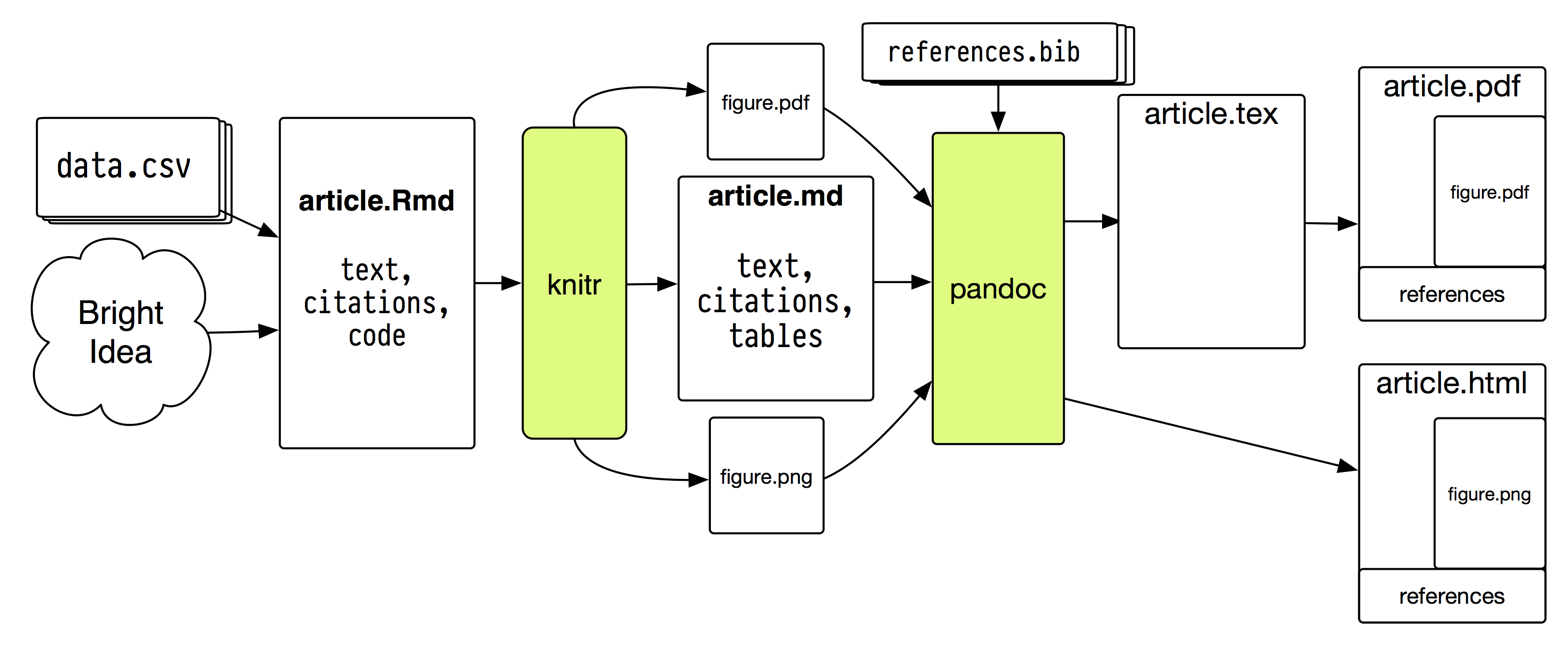
Figure 5.1: A plain-text document toolchain.
图 5.1 显示了一个示例文档流程。我保证它看起来没有这么疯狂。一次性描述它可能听起来有点疯狂。但本质上只有两个可分离的部分。首先,knitr 将 .Rmd 文件转换为 .md 文件。其次,John MacFarlane 出色的 Pandoc 将 .md 文件转换为 HTML、.tex、PDF 或 Word 格式。在这两种情况下,我们使用几个开关、模板和配置文件来漂亮地完成这件事,只需最少麻烦。你应该安装一套标准的 Unix 开发者工具(在 OS X 上可以直接从命令行方便地安装),以及 R、knitr、pandoc 和 TeX 发行版。请注意,knitr 和 pandoc 的默认设置——这一过程中的两个关键部分——已能做我们想要的大部分事情,无需进一步调整。我在这里要告诉你的是使用这些工具的相关选项和开关,以及一些模板和文档示例,展示如何在实践中产生漂亮的输出。
我在 Emacs 中写所有东西,但正如现在应该清楚的,这并不重要。使用你喜欢的任何文本编辑器,并彻底学会它。自定义 LaTeX 样式文件最初是为了让我直接编写好看的 .tex 文件而整理的,但现在它们在后台工作。Pandoc 在将事物转换为 PDF 时会使用它们。繁重的工作由 org-preamble-pdflatex.sty 和 memoir-article-styles 文件完成。如果你将这些文件安装在 LaTeX 能找到的地方——即如果你能基于这个示例编译 LaTeX 文档——那么你就准备好了。我的 BibTeX 主文件也可用,但你可能想使用自己的文件,并在模板中相应地更改对它的引用。其次,我们有自定义的 pandoc 东西。这是它的仓库。那里的大部分材料设计用于 ~/.pandoc/ 目录,pandoc 期望在其配置文件中查找。我还设置了一个示例 md-starter 项目和一个 rmd-starter 项目。这些是论文项目文件夹的骨架,一个是用 Markdown 编写(只是 .md 文件,没有 R),另一个以 .Rmd 文件开始生命。示例项目包含基本的启动文件和 Makefile,用于生成 .html、.tex、.pdf 和 .docx 文件。
Listing 2: Markdown file with document metadata
---
title: "A Pandoc Markdown Article Starter"
author:
- name: Kieran Healy
affiliation: Duke University
email: kjhealy@soc.duke.edu
- name: Joe Bloggs
affiliation: University of North Carolina, Chapel Hill
email: joebloggs@unc.edu
date: January 2014
abstract: "Lorem ipsum dolor sit amet."
...
# Introduction
Lorem ipsum dolor sit amet, consectetur adipisicing elit,
sed do eiusmod tempor incididunt ut labore et dolore magna
aliqua [@fourcade13classsituat]. Notice that citation.
# Theory
Lorem ipsum dolor sit amet, consectetur adipisicing
elit, sed do eiusmod tempor incididunt ut labore et
dolore magna aliqua [@fourcade13classsituat].
让我们从一个简单的 markdown 文件开始——暂时还没有 R 代码,因此在图 5.1 中 article.md 线的左边什么都没有。示例 article-markdown.md 文件的开头显示在清单 5.1 中。顶部的位是元数据,pandoc 理解它。pandoc-templates 仓库中的 HTML 和 LaTeX 模板设置为正确使用此元数据。
对于学术工作,高效管理引用尤为重要。pandoc-citeproc 过滤器是处理这些的附加组件。它可以与 pandoc 一起安装。你的参考文献可以存储在多种格式之一中(如 BibTeX 或 EndNote)。在你的 .md 文档中,引用通过其键引用,如 [@healy14datavisualsociol]。当 pandoc 转换文档时,引用键被替换为参考文献信息,像这样(Healy & Moody,2014),完整的文献条目被包含在自动生成的参考文献列表中。阅读 Pandoc 的文档以了解更多关于引用的详细信息。Pandoc 还可以处理文内标签和交叉引用。名为 pandoc-crossref 的过滤器扩展了@label 约定,以处理图形、表格、方程式、定理、代码清单等。
在 pandoc 管理引用方面有多种方法,但这里我们只使用最独立的路线。简单文档可以包含在单个 .md 文件中。包含数据分析的文档以 .Rmd 文件开始生命,然后被编织成 .md 文件并转换为 PDF 或 HTML。在最简单的情况下,mypaper.md 文档可以通过打开终端窗口并键入清单 3 中的命令转换为 mypaper.pdf 文件。
Listing 3: The simplest way to convert a Markdown file to PDF with pandoc
pandoc mypaper.md -o mypaper.pdf
使用 make 实现自动化
因为我们可能会经常运行这样的命令,所以自动化它们一点很方便,并添加一些额外的功能来处理我们常规添加到文件中的东西,如作者信息和其他元数据,以及处理文献信息和交叉引用的能力。这些通过 pandoc 命令中的各种开关处理,并确保存在几个外部“过滤器”来管理参考文献和交叉引用。与其反复键入长命令,不如自动化这个过程。当最终输出文件可能有多个先决条件才能正确产生,我们希望计算机能够智能一点,知道什么需要重新处理以及在什么条件下需要重新处理时,这种自动化特别有用。这样,例如,如果图形没有更改,我们将不再重新运行(可能耗时的)R 脚本来创建它,除非必须。
我们使用名为 make 的工具来管理这个过程。在项目文件夹中,我们放置一个纯文本 Makefile,其中包含一些关于如何产生可能有多个先决条件的目标文件的规则。在这种情况下,PDF 或 HTML 文件是目标,各种图形和数据表是先决条件——如果产生先决条件的代码更改,最终文档也会更改。Make 从最终文档开始,沿着先决条件链向后工作,按需重新编译或重新创建它们。这是一个强大的工具。要获得良好基本介绍,请查看 Karl Broman 的 "Minimal Make"。(顺便说一句,Karl Broman 有许多教程和指南,准确简洁地介绍这里描述的许多工具和主题,包括如何开始可重现研究、使用 git 和 GitHub 以及使用 knitr。)
遵循 Karl Broman 的例子,想象你有一篇用 Markdown 编写的论文 paper.md,其中包含对由 R 脚本 fig.r 生成的图形 fig1.pdf 的引用。你当然可以有产生输出的 .Rmd 文件,但有些情况下这不理想。终点或目标是 PDF 格式的完整文章。当 paper.md 中的论文文本更改时,paper.pdf 将需要重新创建。同样,当我们更改 fig1.r 的内容时,fig1.pdf 将需要更新,因此 paper.pdf 也需要重新创建。使用 make 我们可以处理这个过程。
Listing 4: A simple Makefile
## Read as "mypaper.pdf depends on mypaper.md and fig1.pdf"
mypaper.pdf: mypaper.md fig1.pdf
pandoc mypaper.md -o mypaper.pdf
## Read as "fig1.pdf depends on fig1.r"
fig1.pdf: fig1.r
R CMD BATCH fig1.r
Makefile 的大陷阱是它们无缘无故使用 Tab 键而不是空格来缩进与规则相关的命令。如果你使用空格,make 将无法工作。使用清单 5.3 中的 Makefile,在命令行键入 make 将让 make 检查最终目标(mypaper.pdf)的状态及其所有依赖项。如果目标不存在,make 将根据指定的规则创建它。如果目标存在,make 将检查其任何先决条件是否在它上次创建后已更改。如果有,它将重新创建文件。先决条件链向后传播,因此如果你更改 fig1.r,make 将注意到并重新运行它以创建 fig1.pdf,然后运行创建 mypaper.pdf 的规则中的命令。你也可以选择只调用 makefile 中的单个规则,例如在命令行键入 make fig1.pdf 而不是 make。这将仅评估 fig1.pdf 规则及任何相关的先决条件。
对于像这样的简单示例,make 主要是一种小便利,省去了你一遍又一遍键入命令序列来创建论文的麻烦。然而,当你拥有具有许多文档和依赖项的项目时——例如由独立章节组成的学位论文,每章都包含图形和表格,而这些又依赖于各种 R 脚本来设置和清理数据——它就变得非常有用。在这些情况下,make 成为确保最终输出真正是最新状态的非常强大和有用的方法。
为了处理更复杂的项目和先决条件链,make 可以利用许多变量来避免(例如)键入目录中每个 figure-x.pdf 的名称。
示例 md-starter 项目中的 Makefile 将根据请求将工作目录中的任何 markdown 文件转换为 HTML、.tex、.pdf 或 .docx 文件。在命令行键入 make html 将从目录中的任何 .md 文件生成 .html 文件。PDF 输出(来自 make pdf)将看起来或多或少像本文。Makefile 的不同部分定义了一些指定不同文件类型之间关系的变量。实质上,规则说,例如,目录中的所有 PDF 文件都依赖于同名 .md 文件的更改;HTML 文件也是如此;等等。然后显示从 markdown 输入生成输出文件的 pandoc 命令。清单中的 Makefile 本身使用一些变量作为简写,以及特殊变量如 $@ 和 $<,分别表示“当前目标的名称”和“当前先决条件的名称”。
Listing 5: A more complicated Makefile
## What extension (e.g. md, markdown, mdown) is being used
## for markdown files MEXT = md
## Expands to a list of all markdown files in the working directory
SRC = $(wildcard *.$(MEXT))
## Location of Pandoc support files.
PREFIX = /Users/kjhealy/.pandoc
## Location of your working bibliography file
BIB = /Users/kjhealy/Documents/bibs/socbib-pandoc.bib
## CSL stylesheet (located in the csl folder of the PREFIX directory).
CSL = apsa
## x.pdf depends on x.md, x.html depends on x.md, etc
PDFS=$(SRC:.md=.pdf)
HTML=$(SRC:.md=.html)
TEX=$(SRC:.md=.tex)
DOCX=$(SRC:.md=.docx)
## Rules -- make all, make pdf, make html. The `clean` rule is below.
all: $(PDFS) $(HTML) $(TEX) $(DOCX)
pdf: clean $(PDFS)
html: clean $(HTML)
tex: clean $(TEX)
docx: clean $(DOCX)
## The commands associated with each rule. The first one is run with
## make html.
%.html: %.md
pandoc -r markdown+simple_tables+table_captions+yaml_metadata_block \
-w html -S --template=$(PREFIX)/templates/html.template \
--css=$(PREFIX)/marked/kultiad-serif.css --filter pandoc-crossref \
--filter pandoc-citeproc --csl=$(PREFIX)/csl/$(CSL).csl \
--bibliography=$(BIB) -o $@ $<
## Same goes for the other file types.
## Watch out for the TAB before 'pandoc'
%.tex: %.md
pandoc -r markdown+simple_tables+table_captions+yaml_metadata_block \
--listings -w latex -s -S --latex-engine=pdflatex \
--template=$(PREFIX)/templates/latex.template \
--filter pandoc-crossref --filter pandoc-citeproc \
--csl=$(PREFIX)/csl/ajps.csl --filter pandoc-citeproc-preamble \
--bibliography=$(BIB) -o $@ $<
%.pdf: %.md
pandoc -r markdown+simple_tables+table_captions+yaml_metadata_block \
--listings -s -S --latex-engine=pdflatex \
--template=$(PREFIX)/templates/latex.template \
--filter pandoc-crossref --filter pandoc-citeproc \
--csl=$(PREFIX)/csl/$(CSL).csl --filter pandoc-citeproc-preamble \
--bibliography=$(BIB) -o $@ $<
%.docx: %.md
pandoc -r markdown+simple_tables+table_captions+yaml_metadata_block \
-s -S --filter pandoc-crossref --csl=$(PREFIX)/csl/$(CSL).csl \
--bibliography=$(BIB) -o $@ $<
clean:
rm -f *.html *.pdf *.tex *.aux *.log *.docx
.PHONY: clean
请注意,pandoc 命令被解释为单行文本,而不是由回车键分隔的多行。但你可以使用 \ 符号告诉 make 在不中断的情况下继续到下一行。使用此 Makefile,键入 make pdf 将依次获取目录中的所有 .md 文件并运行 pandoc 命令将每个文件转换为 PDF,使用 APSR 参考样式、我的 LaTeX 模板和名为 socbib-pandoc.bib 的 .bib 文件。
你不应该盲目使用此 Makefile。花点时间学习 make 的工作原理以及它如何帮助你的项目。官方手册相当清晰。Make 的向后看的先决条件链可能使其难以编写复杂项目的规则。在编写或检查 Makefile 及其特定规则时,使用 --dry-run 开关可能会有帮助,如 make --dry-run。这将打印出 make 将运行的命令序列,但实际上不执行它们。你可以在至少包含一个 .md 文件的目录中尝试清单 5 中的 Makefile。例如,查看 make pdf --dry-run 或 make docx --dry-run 或 make clean --dry-run 产生的命令。
许多项目所需的特定步骤可能相当简单,不需要使用任何变量或其他装饰。如果你发现自己反复运行相同的命令序列来组装文档(例如清理数据;运行初步代码;生成图形;组装最终文档),那么 make 可以大大自动化这个过程。要查看执行与数据分析相关的操作的 Makefile 的进一步示例,请参见 Lincoln Mullen 关于他使用 make 管理的事物的讨论。
示例目录包含一个示例 .Rmd 文件。文件中的代码块提供了如何在文档中生成表格和图形的示例。特别是,它们显示了一些可以传递给 knitr 的有用选项。查阅 knitr 项目页面以获取大量文档和更多示例。要从 article-knitr.Rmd 文件生成输出,你当然可以在工作目录中启动 R,加载 knitr,并处理文件。这将生成 article-knitr.md 文件,以及 figures/ 文件夹中的一些图形(和 cache/ 文件夹中的一些工作文件)。我们在 .Rmd 文件中设置,让 knitr 生成 R 生成的任何图形的 PNG 和 PDF 版本。这为轻松转换为 HTML 和 LaTeX 做好准备。一旦生成 article-knitr.md 文件,就可以像以前一样通过在命令行键入 make 来生成 HTML、.tex 和 PDF 版本。但当然,没有理由 make 不能也自动化第一步。rmd-starter 项目有一个示例 Makefile,从目录中的 .Rmd 文件开始并从此生成输出。
6. Emacs 入门工具包
逐步指南,介绍下载和安装我迄今为止提到的每个软件,这超出了本讨论的范围。但假设你决定冒险并下载了 Emacs、TeX 发行版、R,甚至可能还有 Git。现在怎么办?如果你要在 Emacs 中工作,有各种可能有帮助但未默认设置的调整和附加组件。为了让事情更容易一些,我维护了一个社会科学 Emacs 入门工具包。它旨在通过为你提供可直接使用的默认设置集合以及自动安装一些重要附加包来平滑 Emacs 的粗糙边缘。我希望,它将帮助你永远避开设置事物的深渊。
Figure 6.1: Emacs in Solarized colors.
入门工具包的动机是什么?Emacs 是一个非常强大的编辑器,但开箱即用不如它可能的那样有用,部分因为许多方便的设置和模式未默认激活。入门工具包是一套很好的默认设置。想法是让你能够下载 GNU Emacs,将入门工具包放入 ~/.emacs.d/,然后开始工作。如果你已经使用 Emacs 并拥有 .emacs 文件或 ~/.emacs.d 目录,入门工具包设计为替换它们,同时为你留出一个可以轻松附加自己定制的地方。
入门工具包设计用于 GNU Emacs。需要 24.4 版(2014 年 10 月发布)或更高版本。它不经修改将无法与 Aquamacs 一起工作。工具包内部的 .org 文件提供了更详细的评论和文档。
安装说明(Mac OS X)
开始之前
如果你想使用入门工具包适用的工具——LaTeX、R、Git、Pandoc 等——那么你需要将它们安装在你的 Mac 上。基础是 Apple 自己的开发者工具套件,允许你自己编译软件并包含 Git 等东西。获得这些工具最直接的方法是安装 Xcode。Xcode 是软件开发人员用于编写 Mac 和 iOS 应用程序的软件。因此它附带了我们不那么感兴趣的一堆东西,但它使安装我们需要的东西变得容易。它可通过 Mac App Store 免费获得。下载后,启动 Xcode,进入 Xcode > Preferences > Downloads,并安装 Xcode 的命令行工具。那时你可以退出 Xcode,再也不使用它。或者,前往 Apple 开发者网站,用你的 Apple ID 登录,单独下载 Xcode 的命令行工具包,无需 Xcode 应用程序。
如果你以前使用过 Emacs 并且已经有 .emacs 文件或 .emacs.d 目录,请备份然后删除它们。有关如何向工具包添加定制的详细信息,请参见下文。
获取入门工具包
你有两个选择。你可以下载工具包的 .zip 文件。这将为你提供最新版本的静态快照。但如果你想跟上工具包的更改,你应该使用 git 克隆源代码,而不是简单地复制静态版本。你应该无论如何都对你的纯文本文档使用版本控制,所以我推荐第二种选择。
先决条件
- 获取 Emacs。入门工具包需要 Emacs 24.4(2014 年 10 月发布)。在此下载 Emacs。或者,如果你熟悉 Homebrew,可以编译并安装它。
- 安装现代 TeX 发行版和 Skim PDF 阅读器。如果你使用 OS X,请在此下载 MacTeX 并安装。工具包设置为使用 Skim PDF 阅读器显示从
.tex文件创建的 PDF 文件。你可以使用其他阅读器,但需要修改 starter-kit-latex.org 文件中的设置。 - 安装 R 和 Pandoc。这些对安装工作并非严格必需,如果你喜欢可以跳过这一步。但你可能会使用它们,如果你还没用过的话。如果你正在进行统计工作,你可能会想使用 R 或 Stata。
- 记下你的用户名或计算机名称。如果你不知道,打开终端应用程序并执行
whoami,获取你的用户名,并执行hostname获取系统名称。你需要知道你的登录名才能正确激活最终定制文件。你也可以(或替代地)使用系统名称。
设置
如果你下载了工具包的
.zip文件,你必须解压缩它,将结果文件夹移动到你主目录的顶层,并重命名为.emacs.d。假设下载的 zip 文件在你的~/Downloads文件夹中,打开终端窗口并执行:$ cd ~/Downloads $ unzip emacs-starter-kit-master.zip $ mv emacs-starter-kit-master ~/.emacs.d或者,如果你使用 git(推荐方法),则使用 git 从 github 克隆入门工具包。打开终端窗口并执行:
$ git clone git://github.com/kjhealy/emacs-starter-kit ~/.emacs.d在 kjhealy.org 文件中,按照该文件顶部的描述更改任何 BibTeX 数据库的路径。
根据上述 o.4 中记录的信息,将入门工具包的 kjhealy.org 文件重命名为
%your-username%.org或%your-systemname%.org。这是你可以在 Emacs 中添加自己进一步定制的地方。启动 Emacs。安装入门工具包后首次启动 Emacs 时,它将尝试联系几个软件包仓库,所以请确保你有互联网连接。工具包主要从官方 GNU ELPA 仓库和 MELPA 仓库下载软件包。每个软件包将被获取、由 Emacs 编译并存储在
~/.emacs.d目录中。这个过程有时在从服务器获取软件包时容易出现小问题,所以请耐心等待。如果它第一次没有获取所有内容,退出并重新启动 Emacs,它将再次尝试。如果问题持续存在——特别是如果你看到消息说 "The package 'auctex' is not available for installation"——你可以按如下方式手动安装软件包。打开 Emacs,执行M-x list-packages,在结果缓冲区中搜索或滚动列表到例如 Auctex,按i标记为安装,然后按x安装它(或它们)。安装好软件包后,重启 Emacs,入门工具包将完成设置。不幸的是,我无法控制这些间歇性安装错误。它们似乎与 Emacs 与 GNU ELPA 软件包服务器通信的方式有关。(可选)一旦 Emacs 运行起来,执行
M-x starter-kit-compile以字节编译入门工具包的文件,加载速度稍快。
使用 Marked
在日常使用中,我发现 Brett Terpstra 的应用程序 Marked 是写作时预览文本非常有用的方式。Marked 将 Markdown 文件显示为 HTML,在 Markdown 文件保存更改时实时更新预览。默认情况下它可以渲染普通 Markdown,并会立即为你工作。但它也支持 pandoc 作为自定义处理器。这意味着它可以管理迄今为止讨论的学术格式的各种额外功能。本质上,你告诉 Marked 运行与上面显示的类似的 pandoc 命令来生成其 HTML 预览。你在 Marked 首选项的 "Advanced" 标签中执行此操作。首选项对话框中的 "Path" 字段包含 pandoc 的完整路径,"Args" 字段包含所有相关命令开关——在我的情况下,与上面的 Makefile 中的相同。
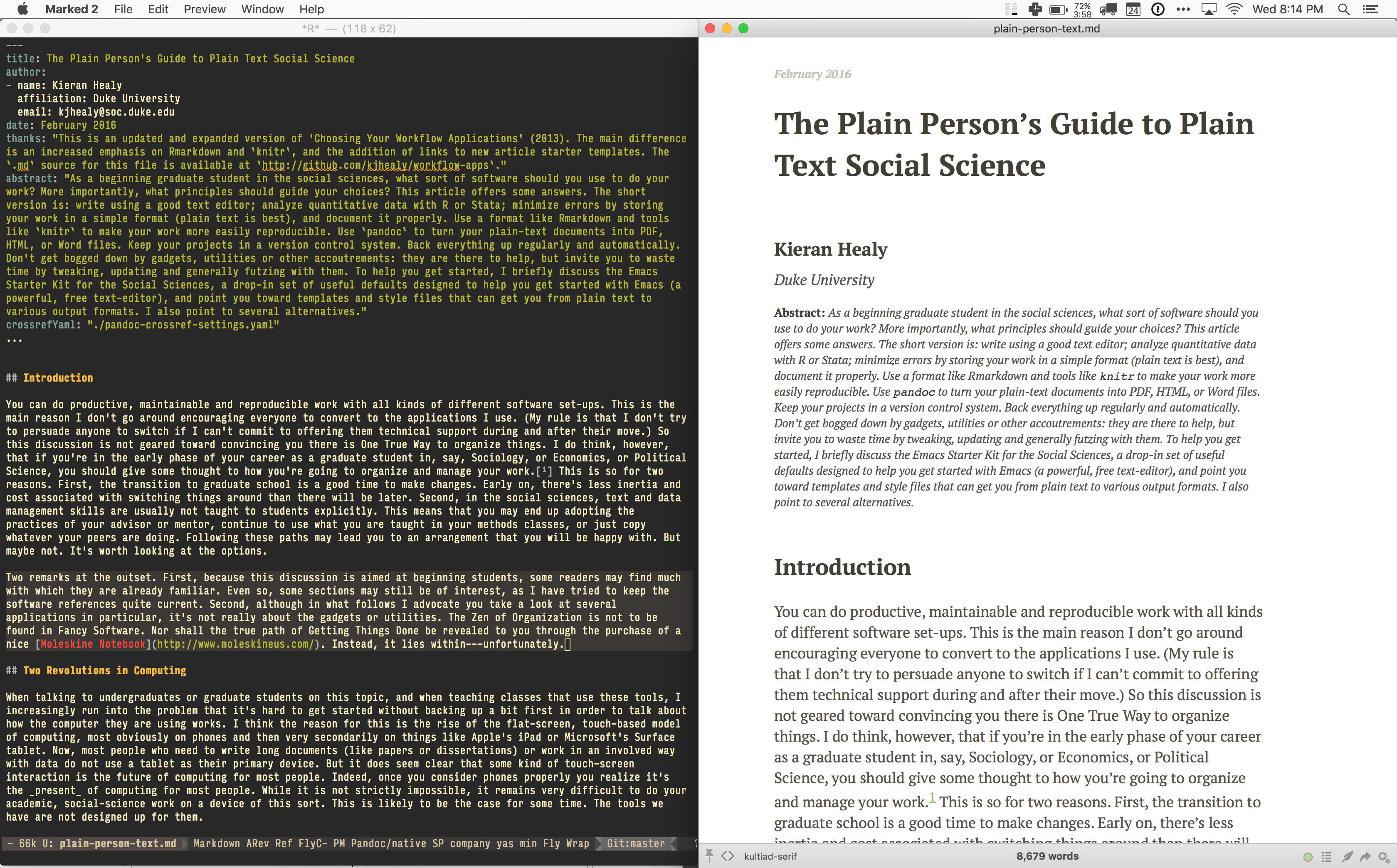
Figure 6.2: Working on this document in Emacs (left), with a live HTML version displayed in Marked (right).
在喜爱的文本编辑器中编辑 markdown 文件时,你将文件指向 Marked 并获得实时预览。你可以通过 Marked 首选项窗口的 "Style" 标签,将 pandoc-templates 仓库中的 CSS 文件添加到 Marked 知道的自定义 CSS 文件列表中。这样,Marked 的预览将看起来与生成的 HTML 文件相同。图 6.2 显示了这在实践中的样子。
所有这一切的结果是使用 Emacs、ESS、R 和其他工具的强大编辑;使用 pandoc 的灵活转换;通过 HTML 和 Marked 的快速简便预览;以及同时(或按需)高质量 PDF 排版。所有这些都可直接从纯文本生成,并将包括大多数学术论文所需的几乎所有机制,最显著的是可在文本中交叉引用的正确标记的表格和图形。虽然以这种方式列出可能看起来相当复杂,但在使用中相当直接,使用时不需要任何思考。我就生活在我的文本编辑器中。各种脚本和设置安静地完成工作,我得到我想要的格式化输出。
7. 我必须使用这些工具吗?
安装、设置等等总是比单纯的使用更困难,而且文档也更加不完善——Jenny 定律
为什么要费心?
在 R 中运行数据分析,在 Markdown 或 RMarkdown 中编写文档,通过 Emacs 或其他文本编辑器执行这两项操作,使用 pandoc 处理它们,使用 Git 跟踪事物,以及(在幕后)使用各种 Unix 工具和 LaTeX……这听起来相当复杂。它有四个主要优点。首先,这些格式、工具和应用程序都是免费的。你可以尝试它们而无需多少金钱支出。(你的时间可能是另一回事,但尽管你不相信我,你现在拥有的比以后更多。)其次,它们都是开源项目,都适用于 Mac OS X、Linux 和 Windows。可移植性很重要,你选择使用的平台的长期可行性也很重要。如果你更改计算系统,你的工作可以轻松移动。第三,它们允许你以可移植、有文档且可重现的方式工作。第四,应用程序紧密集成。一切(包括版本控制)都可以在 Emacs 内部工作。所有它们都可以直接或利用其他工具进行协作。
这些工具都不是完美的。它们可以为你做非常有用和重要的事,但它们不是魔法。与纯文本工作相关的有坏习惯,就像与在 Word 中写所有东西相关的有坏习惯一样。这些工具强大,但学习起来可能乏味。然而,你不必一开始就全部使用它们,或立即了解它们的一切——你现在真正、真正需要立即开始做的唯一事情是做好备份。有很多方法可以整体或部分尝试这些工具。你可以先尝试在 Markdown 中写东西,使用任何文本编辑器。你可以开始使用 R 与 RStudio。修订控制从项目开始实施时更有益,而当你致力于项目更改时则最好。但它可以随时添加。
你也不注定要永远使用这些应用程序。RMarkdown 和(尤其是)Markdown 文档可以转换为许多其他格式。你的文本文件可在任何其他文本编辑器中编辑,也可在任何其他计算机上编辑。统计代码本质上可移植性较低,但 R 的开放性意味着它不太可能很快过时或无法访问。在日常使用中,你可能会发现文档以手机或计算机上记下的纯文本、Markdown 格式笔记开始生命;然后它们变成增长引用和图形等的更长 .md 文件;最终,如果你获得合作者或到了向期刊投稿的时候,它们会迁移到 Word 或 Google Docs 或类似的东西。
这些特定应用程序的缺点是,在你的领域中,相对于其他人,你可能处于少数。在 R 的情况下,这越来越不真实,最近对于 Git 等工具也是如此。用 RMarkdown 或 Markdown 撰写论文较少见。大多数人使用 Microsoft Word 撰写论文,如果你与(你不能指挥的)人合作,这可能是个问题。通常使用 Word 等应用程序比将人们转换为纯文本工作流程更容易。如果你这样做了,至少在跟踪文档更改和管理数据分析代码和输出方面尝试实现这里讨论的某些原则。
但其他选择可能更适合你
根据需求、个人偏好、愿意支付一些钱,或希望在特定平台上工作,你可能将许多其他应用程序置于工作流的中心。对于文本编辑尤其如此,选择众多。在 Mac 上,优质编辑器包括 BBEdit(深受许多 Web 开发人员喜爱,但对 R 的支持相对有限,仅限于语法高亮)和 TextMate 2(如图 7.2 所示)。在 Linux 上,Emacs 的标准替代品是 vi 或 Vim,但还有许多其他选择。对于 Windows,有 Textpad、WinEdt、UltraEdit 和 NotePad++ 等。这些应用程序大多数对 LaTeX 有强大支持,有些也对统计编程有良好支持。
Figure 7.2: Part of an R file being edited in TextMate.
Sublime Text 3 是一个跨平台文本编辑器,正在活跃开发中,用户群日益增长。Sublime Text 快速、流畅,包含基于 Python 编程语言的强大插件系统。在 Emacs 和 ESS 的替代品中,Sublime Text 独特地包含一个开发良好的 REPL,允许轻松在编辑器内部运行 R。Sublime Text 花费 70 美元。
Figure 7.3: RStudio running on Windows.
对于使用 R 的不同方法——以及如本指南中反复指出的——你应该考虑 RStudio。如图 7.3 所示的截图。虽然它在本讨论中出现得相当晚,但它很可能是你的首选。我在教学时使用它。它不是文本编辑器,而是 "IDE",集成开发环境。你的代码和图形,连同 R 控制台、文档和其他输出,都显示在 RStudio 应用程序窗口的不同窗格和标签中。数据和脚本文件通过各种窗口和菜单管理。RStudio 适用于 Mac OS X、Windows 和 Linux。它与 R 的帮助文件集成得很好。它理解 knitr 和 Git。如前所述,它对 Rmarkdown 有全面支持,并为你轻松生成 HTML、PDF 和其他格式。它无疑是进入使用 R 的最简单方式,并提供了一种直接管理这里讨论的许多工具的方法。
对于社会科学中的统计分析,R 的主要替代品是 Stata。Stata 不是免费的,但像 R 一样,它多功能、强大、可扩展,适用于所有主要计算平台。它有大量用户贡献的软件。在最新版本中,其图形功能有了很大改进,其编辑器也是如此。ESS 可以像为 R 一样高亮 Stata 的 .do 文件。其他编辑器也可以设置为与 Stata 一起工作。最近,Python 在社会科学中越来越频繁地使用。Python 是一种相对容易学习的通用计算语言。它经常用于在 R 或 Stata 等应用程序中进行分析之前操作、切割和清理数据。但它在自身权利上也日益成为科学计算平台。SciPy 是学习 Python 在这方面能力的有用起点。像 R 和 RMarkdown 一样,它通过 iPython Notebook 等工具对文学编程有良好支持。自然地,Emacs 对使用 Python 也有良好支持。
在社会科学家当中,修订控制可能是我讨论的工具中使用最少的。但我确信它是长期来看最重要的。虽然像 Git 这样的工具在概念和实践上都需要一点适应,但它们提供的服务极其有用。在大多数上述文本编辑器中结合使用版本控制已经相当容易。也有像 Tower 这样功能齐全的客户端,允许你在不使用命令行的情况下管理 git。从长远来看,版本控制可能通过中介服务甚至作为操作系统基本功能的一部分而更广泛地可用。
更广阔的视角
如果完成工作所需的一切只是一盒软件技巧和捷径,那就太好了。但当然,这比那更复杂。为了能够写论文,你需要有足够的组织性来阅读正确的文献,可能收集了一些数据,最重要的是首先提出了一个有趣的问题。 没有软件会为你解决这些问题。过分关注设置的细节会妨碍你的工作。事实上——我从经验中说——这种关注本身就是一种自我施加的分心,在短期内缓解与工作相关的焦虑,同时为以后储存更多焦虑。在硬件方面,存在荒谬的生产力对应物,即享乐跑步机(hedonic treadmill),由于某种原因,很难完成待办事项列表,即使你所在的咖啡馆包含的计算能力比 1965 年五角大楼的还多。在软件方面,软件的主要恶习是倾向于浪费你大量时间安装、更新和常常沉迷于它。更一般地说,高效的工作流习惯本身只是完成你真正感兴趣的项目、制作你想做的东西、找到带你来研究生院的问题答案的手段。创意生成和项目管理的过程也可以运行得很好,甚至选择项目应该是什么的业务也可以。但这里不是那个地方——我也不是那个人——来提供这方面的建议。
所有这些都只是为了重申两件事。首先,我倡导这些工具不是基于它们会让你更“高效”的理由。相反,它们可能帮助你保持对自己先前工作的控制——并能够重现它。这是一个重要的区别。如果你关心在数据分析中获得正确答案,或者至少能够重复获得同样可能是错误的答案,那么增强这种控制的工具应该对你有吸引力。其次,即使有这个警告,重要的仍然是工作流管理的原则。软件只是达到目的的手段。 我认识的最聪明、最高产的一个人,他一半职业生涯在打字机上写作,另一半在古老的 IBM Displaywriter 上写作。他对拥有过时硬件的备份解决方案是在附近的壁橱里备有一台备用 Displaywriter,以防第一台坏了。它从未坏过。
8. 其他资源链接
基础工具
- Apple 的开发者工具 Unix 工具链。直接使用
xcode-select --install安装,或只是尝试从终端使用例如 git,让 OS X 提示你安装工具。 - Homebrew 包管理器。安装这里几个工具的便捷方式,包括 Emacs 和 Pandoc。
- Emacs。强大的文本编辑器。在 Emacs for Mac OS X 上有可直接使用的 Mac 版本。
- R。统计计算平台。
- knitr。从 R 内部生成可重现的纯文本文档。
- Python 和 SciPy。Python 是一种通用编程语言,越来越多地用于数据操作和分析。
- RStudio。R 的 IDE。进入使用 R 和 RMarkdown 的最直接方式。
- TeX 和 LaTeX。排版和文档准备系统。你可以直接以
.tex格式编写文件,或者只需让它在后台供其他工具使用。MacTeX 发行版是 OS X 上安装的版本。 - Pandoc。将纯文本文档与多种格式相互转换。可以使用 Homebrew 安装。务必同时安装 pandoc-citeproc 以处理引用和文献,以及 pandoc-crossref 以生成交叉引用和标签。
- Git。版本控制系统。与 Apple 的开发者工具一起安装,或通过 Homebrew 获取最新版本。
- GNU Make。你告诉 make 创建文档或程序各部分的步骤。当你编辑和更改各个部分时,它自动计算出哪些部分需要更新和重新编译,并发出执行此操作的命令。参见 Karl Broman 的 Minimal Make 以获得简短介绍。Make 将随 Apple 的开发者工具自动安装。
- lintr 和 flycheck。促使你编写更整洁代码的工具。
辅助工具与模板
- 社会科学 Emacs 入门工具包。设置 Emacs 以使用本指南中描述的许多工具。
- Pandoc 模板。LaTeX 和 HTML 模板,连同 Pandoc 配置文件和其他使用 Pandoc 从纯文本源生成好看的 PDF、HTML 和 Word 文档所需的东西。
- md-starter 项目和 rmd-starter 项目。假设你已安装工具和 Pandoc/LaTeX 模板,这些骨架项目文件夹包含基本的
.md或.rmd启动文件和 Makefile,用于生成本指南中描述的.html、.tex、.pdf和.docx文件。 - RMarkdown 备忘单。Markdown 和 RMarkdown 约定概述。
- RStudio 备忘单。其他快速指南,包括更全面的 RMarkdown 参考和有关使用 RStudio IDE 的信息,以及 R 中的一些主要工具。
指南
- R 风格指南。编写可读代码。
- Jenny Bryan 的 Stat 545。由不列颠哥伦比亚大学 Jennifer Bryan 教授的数据分析课程笔记和教程。大量有用材料。
- knitr 演示。由其作者 Yihui Xie 提供的 knitr 文档和示例。还有一本更详细地涵盖相同内容的 knitr 书籍。
- RStudio 制作者的 Rmarkdown 文档。大量好示例。
- 普通人指南。本项目的 git 仓库。
- Karl Broman 的教程和指南。准确简洁地介绍这里描述的许多工具和主题的指南,包括如何开始可重现研究、使用 git 和 GitHub 以及使用 knitr。
- 用于 OCR 和转换 Shapefile 的 Makefile。Lincoln Mullen 在数据分析流程中 Makefile 的进一步示例。
- 用于 OCR 和转换 Shapefile 的 Makefile。Lincoln Mullen 在数据分析流程中 Makefile 的进一步示例。
付费应用与服务
- Backblaze。安全的异地备份。
- Crashplan。安全的异地备份。
- GitHub。免费托管公共 Git 仓库。付费托管私有仓库。也是其他人编写的公开可用代码(如 R 包和实用程序)的来源。
- Marked 2。Markdown 文档的实时 HTML 预览。仅 Mac OS X。
- Sublime Text。基于 Python 的文本编辑器。
- Zotero、Mendeley 和 Papers 是包含 PDF 存储、注释和其他功能的引用管理器。Zotero 可免费使用。Mendeley 有高级层级。Papers 在试用期后是付费应用程序。我不太使用这些工具,但这并非出于任何强烈的原则性原因——主要是惯性。如果你使用其中一个并想与这里的材料集成,只需确保它能导出到 BibTeX/BibLaTeX 文件。我最近使用最多的 Papers 可以方便地以 pandoc 格式等输出引用键。
参考文献
- Dalgaard, P. (2008). Introductory statistics with R (Second edition). New York: Springer.
- Fox, J. (2002). An R and S-Plus companion to applied regression. Thousand Oaks: Sage.
- Gelman, A., & Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models. New York: Cambridge University Press.
- Harrell, F. (2016). Regression modeling strategies (Second). New York: Springer.
- Healy, K., & Moody, J. (2014). Data visualization in sociology. Annual Review of Sociology, 40, 105–128.
- Maindonald, J., & Braun, J. (2003). Data analysis and graphics using R: An example-based approach. New York: Cambridge University Press.
- Matloff, N. (2011). The art of R programming. San Francisco: No Starch Press.
- Venables, W. N., & Ripley, B. D. (2002). Modern applied statistics with S (Fourth). New York: Springer.
- Xie, Y. (2015). Dynamic documents with R and knitr (Second). New York: Chapman & Hall.